
10月27-28日,由高校毕业生就业协会主办,江南大学、江苏信息职业技术学院等承办的高校毕业生就业协会教育数字化服务工作委员会暨高校教育数字化转型与人才培养论坛在江苏省无锡市圆满召开,迪塔维作为支持单位受邀出席。席间,迪小数发现很多老师对我们的“职业院校大数据中心”建设方案非常感兴趣,所以本期话题,我们就本着探究与学习的态度,与大家一起聊聊《全国职业院校大数据中心建设指南》(以下简称“指南”)中的大数据中心怎么建。
说起“指南”,今年6月份,教育部教育管理信息中心印发《职业教育信息化标杆学校建设指南》、《职业教育信息化标杆学校监测指标》、《职业院校大数据中心建设指南》系列指导文件,目标到2025年,建设300所左右数字资源丰富、功能应用强大、赋能效果良好、示范引领突出的全国性标杆校,带动建设1000所左右区域性标杆校,引导职业院校进一步丰富拓展师生发展、教育教学、实习实训、管理服务等方面的应用场景,以数字化赋能职业院校教学模式深度变革,促进数字技术与教育教学深度融合,带动职业教育数字化水平整体提升,服务数字时代高素质技术技能人才培养。
职业院校数字校园建设试点是标杆校建设的重要基础。数字校园试点工作中,建设校本大数据中心、对接院校中台、参与国家智慧职教平台资源与应用建设等任务,既是参与标杆校建设的基础条件,也是标杆校建设任务的重要组成。“指南”是职业院校校本大数据中心建设、应用、运维工作的规范和指导。简而言之,建设标杆校,需要根据“指南”要求,不断完善校本数据中心。
其实看到“指南”,我们也是惊喜且兴奋的,因为学校能够知道大数据中心怎么建,我们也能看到自己的产品与“国家队”的差距。欣慰的是,逐条对标后,我们发现产品与“指南”要求高度吻合,而“指南”中对专有名词的释义更加权威、合理,这也为我们后续产品的优化提供了明确的方向。
一、“What to do?”/
学校大数据中心建设主要包括顶层设计、数据标准与数据架构设计、数据质量与安全管理、数据应用、大数据平台建设、全国职业教育智慧大脑院校中台对接等内容。我们的理解,顶层设计是策略,标准与架构设计是核心,质量与安全是保障,应用是路径,大数据平台是工具,智慧大脑对接是前提。
二、“How to do?”/
“指南”中“大数据中心平台技术框架”章节详细描述了服务大数据中心建设所需的技术结构和工具(如图所示),采用分层结构,包括数据源层、数据汇聚层、数据存储与管理层、数据分析与开发层、数据应用层、以及数据治理监控层。所谓“工欲善其事,必先利其器”,数据为基,数链为线,治用并举,方为“智”治。


▲ 大数据中心平台工具框架图


▲ 迪塔维大数据中心总体架构图
我们一层一层来看:
数据源
数据源从类型上可分为结构化数据、半结构化数据及非结构化数据;从来源上可分为校内数据(业务数据)及校外数据(互联网数据)。随着物联网及融媒体技术的蓬勃发展,教学课件、安防视频、人车进出照片、OA发文的各类附件文档等非结构化数据和校外互联网数据以日益增长的态势,成为数据治理、数据分析的一大重要组成,同样大数据中心也要将此类数据纳入治理口径。
数据汇聚
“数据汇聚作为底层基础支撑性服务,是大数据环境的基础组成部分。通过Datax、Kettle等主流ETL工具对学校的多源异构数据汇聚需考虑不同类型(结构化、半结构化、非结构化)、不同集成策略(定期采集、实时采集)的数据汇聚方案,并支持数据的预处理,为大数据环境提供原始数据支撑。”
Datax、Kettle等工具虽主流,但操作繁琐,实时集成需要外挂其他引擎,依然属于传统的ETL模式,我们的破局之法是:通过流批一体数据集成引擎,实现各类异构数据源(包括非结构化数据)的统一汇聚,通过实时湖仓完成数据分层建设,实现标准化数据的清洗转换等处理过程。只要源端满足条件,流处理引擎就可以适配各类主流关系型数据库的实时同步,将CDC(变化数据捕捉)的制约条件降至最低,支持逻辑主键、物化视图、BlOB大字段的实时同步,并提供集成策略推荐。通过可视化的配置界面,将繁琐的操作黑盒化,降低数据汇聚作业的开发难度。
另外,批处理又保留了ETL工具强大的批量计算及数据清洗转换能力,基于统一调度实现各类集成任务的在线编排和调度,与流处理自由切换,即“流批一体”,为每个高校的数据汇聚场景适配最优的数据同步方案。
数据存储与管理
“数据存储与管理层是大数据处理环境的核心,它存储由数据采集层采集回来的各类数据和数据治理后的各个层次的数据,并为上层应用提供数据处理的能力。” 显然,这是大数据中心的核心所在。大数据底座支撑大数据中心数据存储、汇聚、交换、传输、计算的全过程,其性能和架构将直接影响大数据环境的运行。
迪塔维大数据底座搭载自研流批一体集成引擎、分布式湖仓、流式数据传输Kafka集群等内置组件,对时效性、稳定性、扩展性和性能进行全面提升,分布式、高容错、高稳定,数据存储体系足够健壮,同时能为用户提供完整的大数据Hadoop生态等技术组件,便于扩展数据存储、计算、调度、共享等延伸需求。

▲ 数据存储与管理逻辑架构图
从数据存储架构划分上来说,我们把数据实体分为数据源层、贴源层数据湖(ODS)、数据仓库标准层(DWD)和数据仓库应用层(ADS)四大部分,数据源通过实时入湖操作1:1复制进入贴源层,经对标、清洗、脱敏后进入数据仓库标准层,围绕学校基础管理范畴划分主题域,应用层则以标准层为基础,构建命名规范、口径一致的数据模型及指标,为上层数据应用输出主题、指标模型。本存储架构与“指南”在“数据架构设计”章节提出的数据贴源层(ODS)、数据仓库层(DW)和数据应用层(ADS)三层分布完全吻合。
数据分析与开发
“数据分析与开发层提供对数据的探查与自主分析和图形化的数据开发。” 我们通过可视化拖拽方式实现数据实时集成、实时计算、脚本开发(SQL、SHELL、PYTHON)、算法开发,为深入挖掘数据要素潜力,我们还提供了一个支持R语言和Python语言编写的Web应用,可以在线创建、编译、运行、共享代码,实现深层次数据清洗转换、数值模拟、统计建模、挖掘算法功能,帮助学校降低数据开发门槛,提高开发效率。支持基础算法原子封装,通过可视化建模过程,实现拖拽式数据智能分析与挖掘工作,发掘数据内在关联关系,深挖数据资产潜在价值,支持预警类、画像类应用精准化助力人才培养、主动关怀。
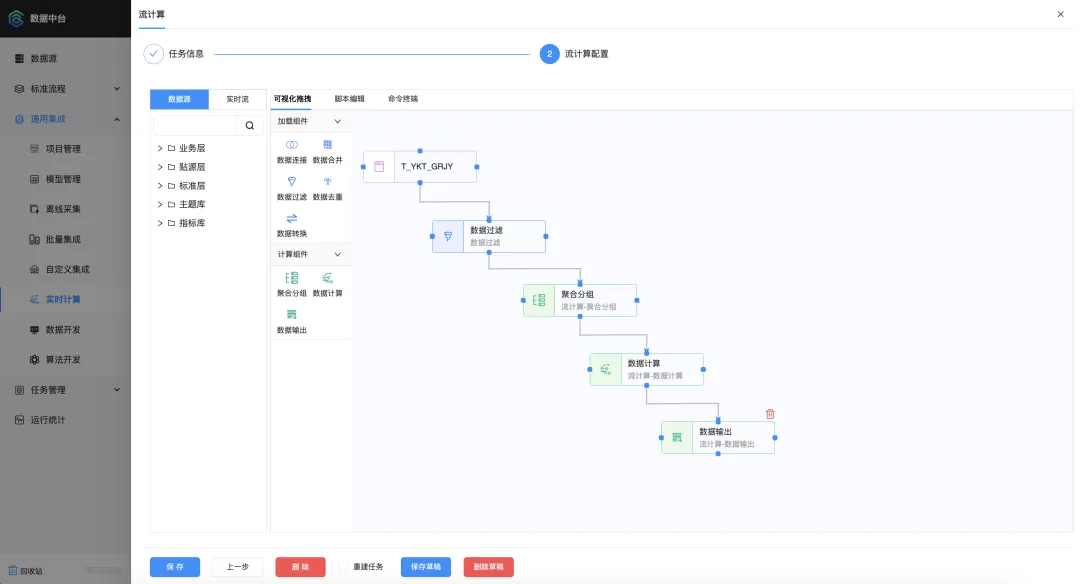
▲ 流计算可视化拖拽配置
数据应用
数据应用层是面向最终用户划分的,分为数据开放共享和数据可视化两部分。我们在数据开放模块提供了全场景、高安全的数据开放与共享接口开发注册及监控能力,围绕数据资产服务的“开发-发布-监控”流程,使数据资源共享更加体系化、流程化。另外,除要求的API接口形式之外,我们还提供在线查询、文件下载、视图开放共四类开放形式。
数据可视化作为最直观可见的数据应用场景,一直是各路厂商“卷技术、秀实力”的主战场。我们不敢保证技术能力是最顶尖的,但是对于高校数据可视化场景下常用的组件、指标非常了解,多年实施经验也积累了丰富的可视化模板,可按需构建领导驾驶舱、主题看板、移动端数据报告、联屏IOC等可视化场景。结合流计算能力,大屏还可实时呈现数据同步、数据统计效果。
数据治理监控
数据治理监控层贯穿数据治理全过程,“指南”中重点提及了数据质量监控、安全监控和需求监控三个方面。我们的想法是对数据的全生命周期和使用痕迹都要形成全面的监控和自动化追溯,数据从产生到消亡的全过程可记录,从源头到终端的所有转换过程可追踪,实现链路式数据管理体系,即“全链路体系”。所以我们的全链路监控中心实现了包括对数据集成过程、数据资源建设情况、数据质量及反馈情况、数据后台实体空间运行情况、数据开放API访问情况、数据血缘及数据应用、数据影响、运行状况等的监控。同时,监控中心还伴有预警功能,可对异常任务提醒及时关注。