
上一篇文章中我们介绍了高校信息化共享数据平台的相关情况,本来应该要继续聊大数据平台了,不过今天我想先插播一则“广告”,你、你、你还记得“大明湖畔的高基报表”吗?为什么插播?因为在共享数据平台、主数据平台的建设阶段,前端的数据应用很难绕开“报表”二字,报表,尤其是高基报表,是那个时代的印记。
报表作为数据仓库最为经典的应用场景,到目前为止也是各行各业最重要数据价值输出形式之一。不过报表这个词应该拆开来解读,分为“报”和“表”两个过程,“表”顾名思义,是展现、是形式;而“报”是个动词,是指如何把数据生成到表里的过程。
“表”应用
在今天文章中我们温故而知新,大家先随我一起回顾一下那些年的“表”应用:
基本校情分析、迎评系统、院系数据分析、综合查询、主题分析等等。这些是最早在教育信息化领域涌现出的数据应用名词。当时数据应用及可视化,最主要的是利用Flash、中国式报表工具、甚至使用浏览器插件、Java小程序来构建前端图表,整体来说“丑”而且交互不灵活。假设使用类似BIEE、Cognos之类的航空母舰级BI工具,则会涉及到高昂的费用,让学校无力承担,如果使用“爱国版”则会担惊受怕,终归不是个终极的解决办法。
在这种自身兵源不足(数据量不够、质量不高)、无粮草(经费不足)、有追兵(各类正版化要求、学校业务要求)的情况下,各个学校信息中心的同仁们还是顶着压力完成了类似教学评估的迎评数据分析、基本校情展示、各类科研、教学主题分析等数据“表”应用,实现了数据呈现到需求认领的过程,可视化报表成为了数据应用的建设主线路,也逐渐一步步发展为今天百花齐放的数据应用格局。

“报”应用
聊完了“表”我们再重点聊一下“报”,也就是数据上报。上报的应用特点有两个,一个是上报的表格有标准样式和内容的要求,二是上报要有审核校对数据的过程。其中高基报表最为复杂,一直到目前为止也是个难题。
高基报表全称《高等教育事业基层统计报表》,高基上报过程一般的开展逻辑是指定一个负责部门,比如校办或者发规处等,将上报任务按照数据口径进行拆解,例如教职工相关数据拆解到人事处,本专科生数据上报任务拆解给教务处,各个部门如果数据基础不好或者不全面,那还要再将上报任务拆解到院系,由院系上报后进行汇集,最终逐层汇集到上报责任部门,部门管理人员再结合数据指标之间的对应、限定关系,结合历史上报数据,结合未来学校发展规划进行“微调”,以此来保证上报的数据的“真实”、“稳定”。
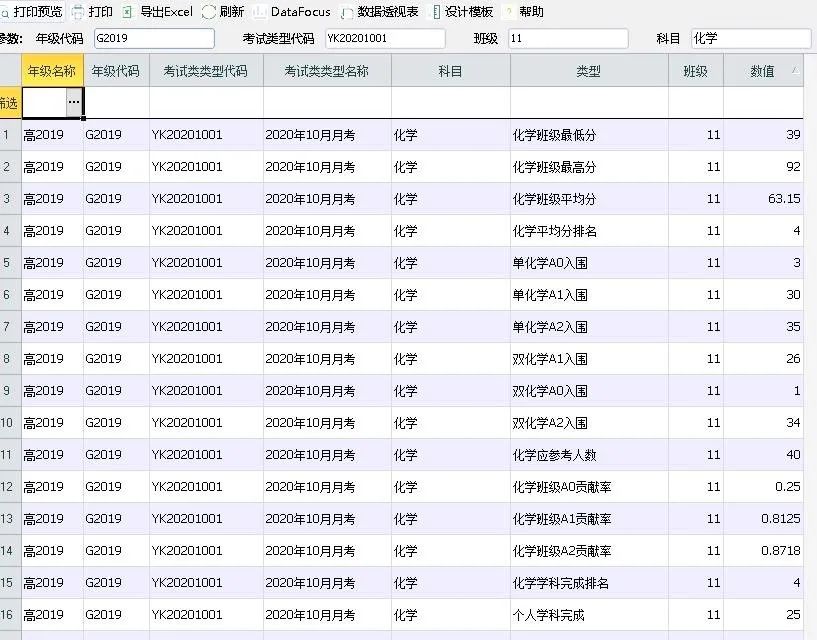

以下这段文字来自互联网搜索引擎,是动员高基上报的发文,大家可以一起品鉴一下高基上报过程的复杂:
一、依法规范统计行为,保证统计数据客观真实。各部门填报过程中要注意各表间关系,确保数据准确连贯、符合逻辑,并认真核实检查,避免出现相互矛盾。
二、各填报部门指定兼职统计员负责填报数据,兼职统计员要认真研究相关表格的指标解释和填报说明,数据交叉部门要协调配合、统一口径,务必使同类数据一致。
三、各填报部门在填报过程中要结合历年数据,准确合理填报今年数据,确保数据增减幅度保持稳定,同时各部门要认真研究数据,合理使用数据,让数据为工作决策提供科学依据。
四、各填报部门填写的报表由兼职统计员签字,部门负责人审核签字,报分管校领导审阅后交纸张稿和电子稿送校办汇总。
高基上报的难点及过程
从上面的描述不难看出,高基上报过程难点很多,总结一下来说包括以下几点:
1、共享数据范围的限制
假设所有数据是真实的,那么一般40多张高基报表中只有60%左右的数据可以依托教育管理信息化标准中的数据集计算产生,剩余40%包括定性数据,依然需要归口部门填报,无法完全自动生成。
2、错综复杂的数据关系
除了真实数据的支撑外,高基上报还要考虑到“连续性”、“稳定性”以及“学校发展的客观需要”,这就有难度了,啥意思?高基数据得尊重历史,尊重事实,还要尊重未来规划,等同于上一柱香得拜燃灯、如来、弥勒三位佛,难度很大啊,只能靠人脑协调解决数据矛盾。
3、周期性重复工作
每年都要重新收集、填报数据,1.5个月左右的工期,很多指标数据并不通用,需要手工计算合并,工作量很大。
4、流程不清晰
一次上报工作经常会涉及20个以上的部门和二级学院,每个学校的具体工作安排也不尽相同,数据之间的交叉会出现一个数据指标涉及几个部门之间的沟通协调,上报过程中扯皮现象时有出现。
那基于共享数据库能不能辅助一下高基上报过程呢,答案是可以,但有限。能做哪些事情?
1、历史数据采集:早期的高基上报数据是DBF文件形式,基于数据转换技术,可以把往年的DBF文件导入到结构化数据库中,方式是每个单元格作为一条记录独立存储,标注单元格序号,由于不同年份的高基报表之间会有格式和指标变化,因此针对每年的数据也要对应做版本化个性处理;
2、自动计算填充:基于共享数据库和高基统计口径,通过SQL语句做计算,基本上count,sum等数据库聚合函数就足够了,毕竟是当年的数据上报,不涉及时间序列,也不涉及数据挖掘算法。只是,共享数据库中所存储的内容不足以支撑高基上报的所有指标要求,很多内容无法自动计算生成,但是通过共享数据库基本上能够覆盖高基50%以上的数据上报项,可以解决一部分数据填报的痛点。
3、数据可视化:共享数据库之上通过中国式报表工具(例如早期的润乾、帆软等)可以快速绘制出前端报表样式,脱离单机的束缚,提供了BS架构的数据可视化的功能。
4、数据比对分析:能够实现历史数据、当前上报数据、自动计算数据三者之间的比对分析,这样的分析虽然意义只限于辅助填报,但毕竟也是共享数据库体系带来的突破。
5、明细数据溯源:基于指标数据可以对应到后端的SQL语句,找出上报指标(例如专任教职工人数)所对应的明细数据,实现商业智能当中常见的数据下钻功能,找出指标背后的依托。
最终高基的上报过程还是需要人为的干预,当下的高基上报工作可以通过全域数据中心逐步提升数据范围和数据质量,实现数据自动计算,同时节省上报时间。但是解决高基上报的难题不能只从上报本身来考虑,整理一堆SQL语句、Excel文档、后台存储过程,并不会带来实质性的进步。
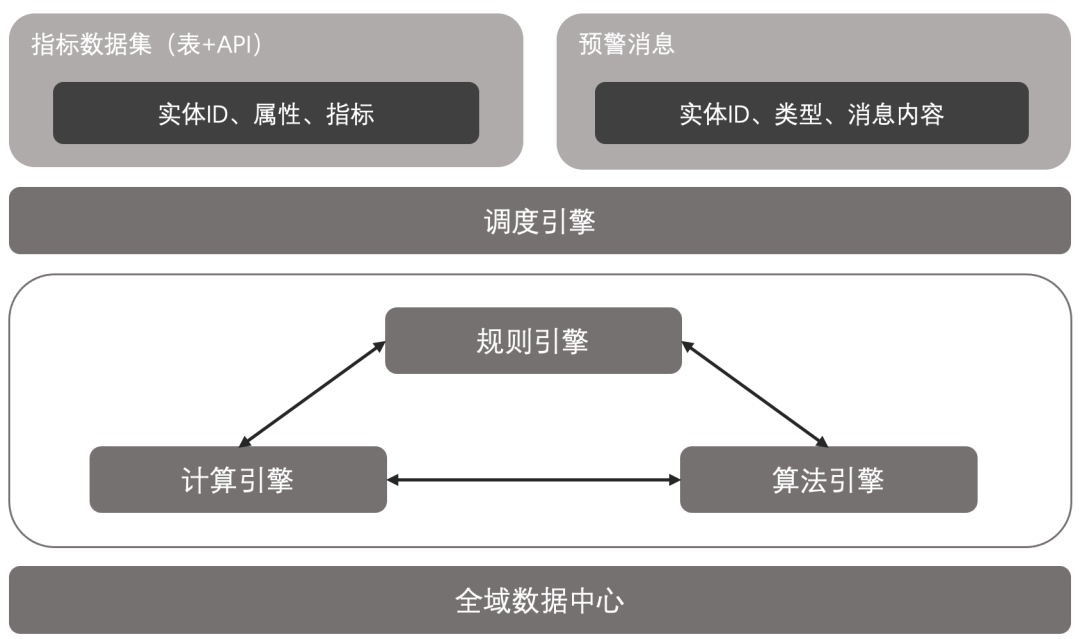
真正要解决问题的办法是,要有一个学校全局的、可迭代、可编辑、可追溯的指标数据管理体系,类似银行的KPI,类似企业管理的核心经营指标。要通过统一的指标管理抽象出高校的核心指标体系,形成学校级、学院级(专业)、部门级、师生级标准的、区分视角的指标及标签,一个ID对应多个场景再对应N个指标,这些指标可以应用在全景画像,也可以用于高基上报、学科评估、教学数据采集、学院综合竞争力对比分析等等,同时指标是业务化的,普通业务人员能够可视可读,能看得懂,指标结合分析工具才能真正驱动数据价值的快速落地。
高基上报给我们的启示,我们需要在基础数据之上形成体系化的业务指标及标签,实现数据价值的外延、实现数据价值的可复用,达成业务场景驱动数据治理的最终目标。
最后再插播一则广告,高校指标管理解决方案、数据可视化解决方案DataV都有,欢迎咨询惠顾。
作者:王珂